
Data Definition Language (DDL)
- Create Table
- Alter Table
- Add a column
- Modify a column
- Drop a column
- Rename a column
- Drop Table
- Whole table and records will be removed.
- Truncate Table
- Remove all records, but table structure still remains.
Constraints
- NOT NULL
- Adheres to not null value in the column.
- Column-level constraint.
- UNIQUE
- Adheres to non-duplicate value in the column.
- Both column and table-level constraint.
- When it’s a table-level, it will check the combinations of values to be unique across all columns in the table.
- PRIMARY KEY
- Adheres to NOT NULL and UNIQUE constraints together.
- A primary key associate to only a single column in a table.
- Composite key: A combination of two or more columns (defined as a primary key) in a table that can be used to uniquely identify each row in the table when the columns are combined uniqueness is guaranteed, but when it taken individually it does not guarantee uniqueness.
- CHECK
- Adheres to check constraint.
- For example: Gender column in a Citizen table has conditional values: M/F only, if you enter other value ‘A’, it will throw error.
- FOREIGN KEY
- Adheres to referential integrity constraint.
- It’s a connector key which helps to fetch additional records from same or other table.
- Make a relationship between two tables based on the primary keys. The primary key on one table becomes the foreign key for other.
Data Manipulation Language (DML)
ORDER BY
The ORDER BY keyword is used to sort the result-set in ascending or descending order.
SELECT * FROM Customers ORDER BY Country;
GROUP BY
The GROUP BY statement is often used with aggregate functions (COUNT, MAX, MIN, SUM, AVG) to group the result-set by one or more columns.
SELECT COUNT(CustomerID), Country FROM Customers GROUP BY Country;
Indexes
- Indexes are special lookup tables that the database search engine can use to speed up data retrieval.
- Simply put, an index is a pointer to data in a table.
- An index in a database is very similar to an index in the back of a book.

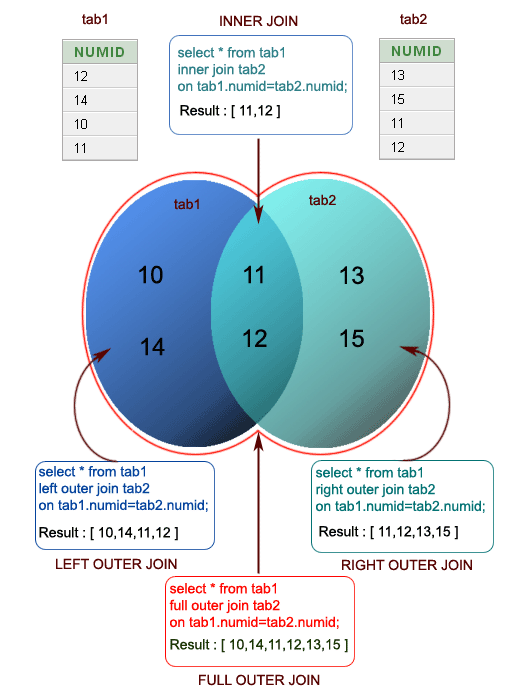
SQL Joins
Normalization
- Normalization is the process of structuring a relational database into normal forms (NF) in order to:
- Reduce data redundancy (repetition)
- Ensure data dependencies (data is logically stored)
- Maintain data integrity
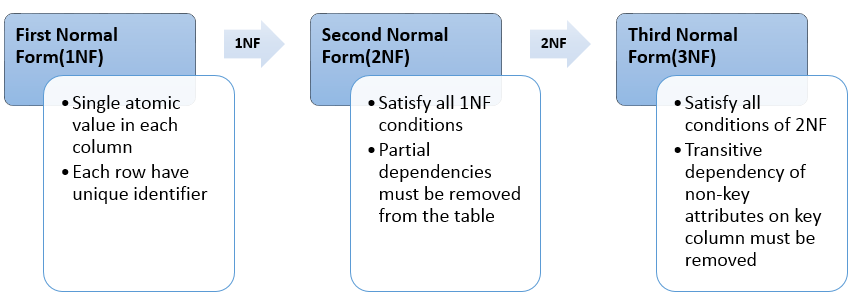
- 1st NF
- Rule 1: Single atomic value in each column
- Example: FirstName column must have first name only, mustn’t have DoB value in it.
- Rule 2: Each row must have a unique identifier
- Example: Each row must have unique id to manage the data.
- Rule 1: Single atomic value in each column
- 2nd NF
- Rule 1: 1st NF must be adhered.
- Rule 2: No partial dependency. i.e., Every non-prime attribute of the table is functionally dependent on the whole of every primary key/ candidate key.
- Functional Dependency is a relationship that exists when one attribute uniquely determines another attribute. If R is a relation with attributes X and Y, a functional dependency between the attributes is represented as X->Y, which specifies Y is functionally dependent on X.
- Partial dependency implies is a situation where a non-prime attribute (an attribute that does not form part of the primary key/ candidate key) is functionally dependent to a part of a primary key/ candidate key.
- Example: Product (Id, Name, Price)
- Candidate Key: Id, Name
- Non prime attribute: Price
- Price attribute only depends on only Id attribute, which is a subset of candidate key, not the whole candidate key (Id, Name) key . It is called partial dependency.
- So we can say that Id-> Price is a partial dependency.
- Solution: To remove Partial dependency, we can divide the table, remove the non-prime attribute which is causing partial dependency, and move to separate table and associate with a primary key/ candidate key.
- Product (Id, Name)
- Price (Id, Price)
- Example: Product (Id, Name, Price)
- 3rd NF
- Rule 1: 2nd NF must be adhered.
- Rule 2: No Transitive Dependency.
- Transitive Dependency is a functional dependency which holds by virtue of transitivity. A transitive dependency can occur only in a relation that has three or more attributes. Let A, B, and C designate three distinct attributes (or distinct collections of attributes) in the relation. Suppose all three of the following conditions hold:
- A → B
- It is not the case that B → A
- B → C
- Then the functional dependency A → C is a transitive dependency.
- Example: BookAuthor (BookName, Genre, AuthorName, AuthorNationality)
- {BookName} → {AuthorName}
- {AuthorName} does not → {BookName}
- {AuthorName} → {AuthorNationality}
- Therefore {BookName} → {AuthorNationality} is a transitive dependency.
- Transitive dependency occurred because a non-key attribute (AuthorName) was determining another non-key attribute (AuthorNationality).
- Solution: To remove Transitive dependency, we can divide the table, remove the non-prime attribute which is causing transitive dependency, and move to separate table and associate with a primary key.
- Book (BookName, Genre, AuthorName)
- Author (AuthorName, AuthorNationality)
- Transitive Dependency is a functional dependency which holds by virtue of transitivity. A transitive dependency can occur only in a relation that has three or more attributes. Let A, B, and C designate three distinct attributes (or distinct collections of attributes) in the relation. Suppose all three of the following conditions hold:
SQL Performance Tips
- Check Indexes
- Have indexes on all fields used in the WHERE and JOIN portions of the SQL statement.
- More indexes could slow down write operations (such as INSERT / UPDATE statements).
- Avoid wrapping indexed columns with functions
- SELECT count(*) FROM us_hotdog_purchases WHERE YEAR(purchase_time) = ‘2018’
- This function call will prevent the database from being able to use an index for the purchase_time column search, because we indexed the value of purchase_time, but not the return value of YEAR(purchase_time).
- SELECT count(*) FROM us_hotdog_purchases WHERE purchased_at >= ‘2018-01-01’ AND purchased_at < ‘2019-01-01’
- Avoid OR conditions
- SELECT count(*) FROM fb_posts WHERE username = ‘Mark’ OR post_time > ‘2018-01-01’
- Having an index on both the username and post_time columns might sound helpful, but in most cases, the database won’t use it, at least not in full. The reason will be the connection between the two conditions – the OR operator, which makes the database fetch the results of each part of the condition separately.
- An alternative way to look at this query can be to ‘split’ the OR condition and ‘combine’ it using a UNION clause. This alternative will allow you to index each of the conditions separately, so the database will use the indexes to search for the results and then combine the results with the UNION clause.SELECT …
FROM …
WHERE username = ‘Mark’
UNION
SELECT …
FROM …
WHERE post_time > ‘2018-01-01’
- Avoid sorting with a mixed order
- Consider this query, which selects all posts from Facebook and sorts them by the username in an ascending order, and then by the post date in a descending order.
- SELECT username, post_type FROM fb_posts ORDER BY username ASC, post_type DESC
- Avoid LIKE searches with prefix wildcards
- SELECT * FROM fb_posts WHERE username like ‘%Mar%’
- Having a wildcard ‘%’ at the beginning of the pattern will prevent the database from using an index for this column’s search.
- Limit Size of Your Working Data Set
- A classic example is when a query initially worked well when there were only a few thousand rows in the table. As the application grew the query slowed down.
- The solution may be as simple as restricting the query to looking at the current month’s data.
- Only Select Fields You Need
- Extra fields often increase the data load in retrieval.
- Data retrieval increase the network IO and disk IO.
- Remove Unnecessary Tables
- Same as the reasons for removing fields not needed in the select statement.
- Remove OUTER JOINS
- One solution is to remove OUTER JOINS by placing placeholder rows in both tables.
- Say you have the following tables with an OUTER JOIN defined to ensure all data is returned:
|
|
- The solution is to add a placeholder row in the customer table and update all NULL values in the sales table to the placeholder key.
|
|
- Not only have you removed the need for an OUTER JOIN you have also standardized how sales people with no customers are represented. Other developers will not have to write statements such as ISNULL (customer_id, “No customer yet”).
